2024年3月8日~9日に国立情報学研究所で行われた第51回ゲーム情報学研究会において、修士2年の山下が、「ローグライクゲームの強化学習を目指した行動の事前学習の試み」の研究発表を行いました。
- 山下 興紀, 横山 大作, ローグライクゲームの強化学習を目標とする,行動の事前学習手法の評価, 第51回ゲーム情報学研究会, 2024.3.8~2023.3.9, (PDF)
研究背景・目的
強化学習によるゲーム攻略は近年盛んに行われており、囲碁であれば「AlphaGo」、将棋であれば「Ponanza」などが有名となりました。しかし強化学習も万能ではなく、学習することを苦手とするゲームが存在します。今回題材として取り上げたローグライクゲームは、「不完全情報」「ランダム性」「疎な報酬」「有効な行動の少なさ」などの性質により、強化学習での学習が困難となっています。実験を進める中で、重要な行動でありながら、学習が困難となっていた「階段を降りる」行動に焦点を絞り、NetHackの実験用環境下で「階段を降りる」行動を高頻度で行えるプレイヤの作成を目標しました。
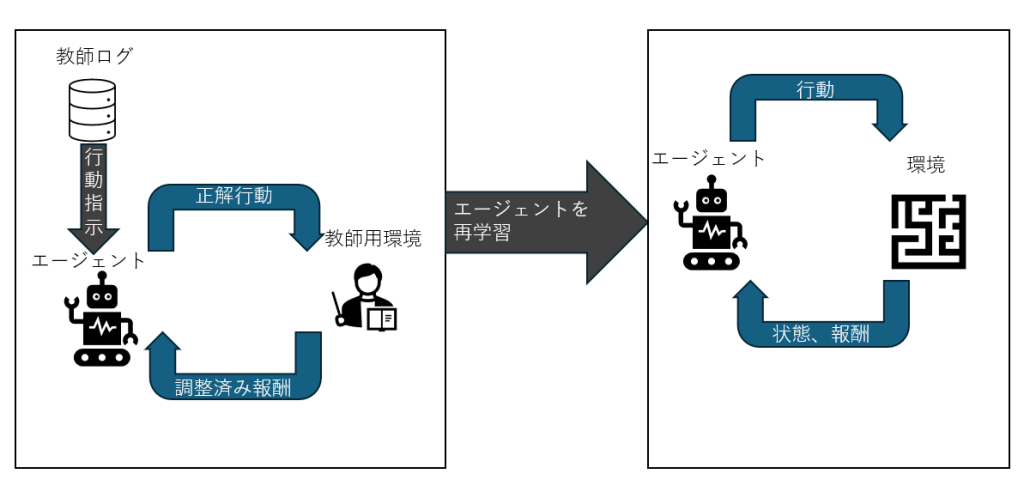
本研究のアプローチ
本研究では、強化学習を行う前の段階で、ヒューリスティックプレイヤが過去にプレイした履歴データを使用し事前学習を行い、事前学習により作成されたエージェントを再学習するアプローチを取りました。学習の際には、事前学習の手法として、模倣学習に使われるアルゴリズム「Behavior Cloning」を使用し、強化学習の手法としては「Proximal Policy Optimization」を使用しています。
結果として、事前学習を行わなかった場合と比較して「階段を降りる行動」の頻度は上昇し、一定の有効性を示すことが出来ました。しかし性能面で、学習元としていたヒューリスティックプレイヤの性能に劣るという課題が残りました。今後の展望として、状態に応じて複数エージェントを用意する事で、対応しきれなかった今回の環境に対して、より良い結果を出せるのではないかと考えています。